Lyst Data Lake migration
During my time at Lyst, we decided we had to redesign the data pipeline architecture due to a few main issues:
- Queries were too slow, and users across the business were unable to iterate on their data easily
- Queries were expensive causing a huge cost to the business
- Erroneous transformed data was stored without the source of truth, and no ability to reprocess the data
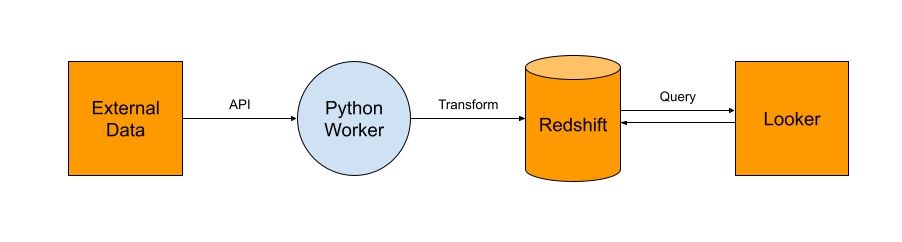
Previous architecture.
The previous architecture was data sent directly from the source, transformed and sent to Redshift. The data was queried with Looker with dashboards which had many joins.
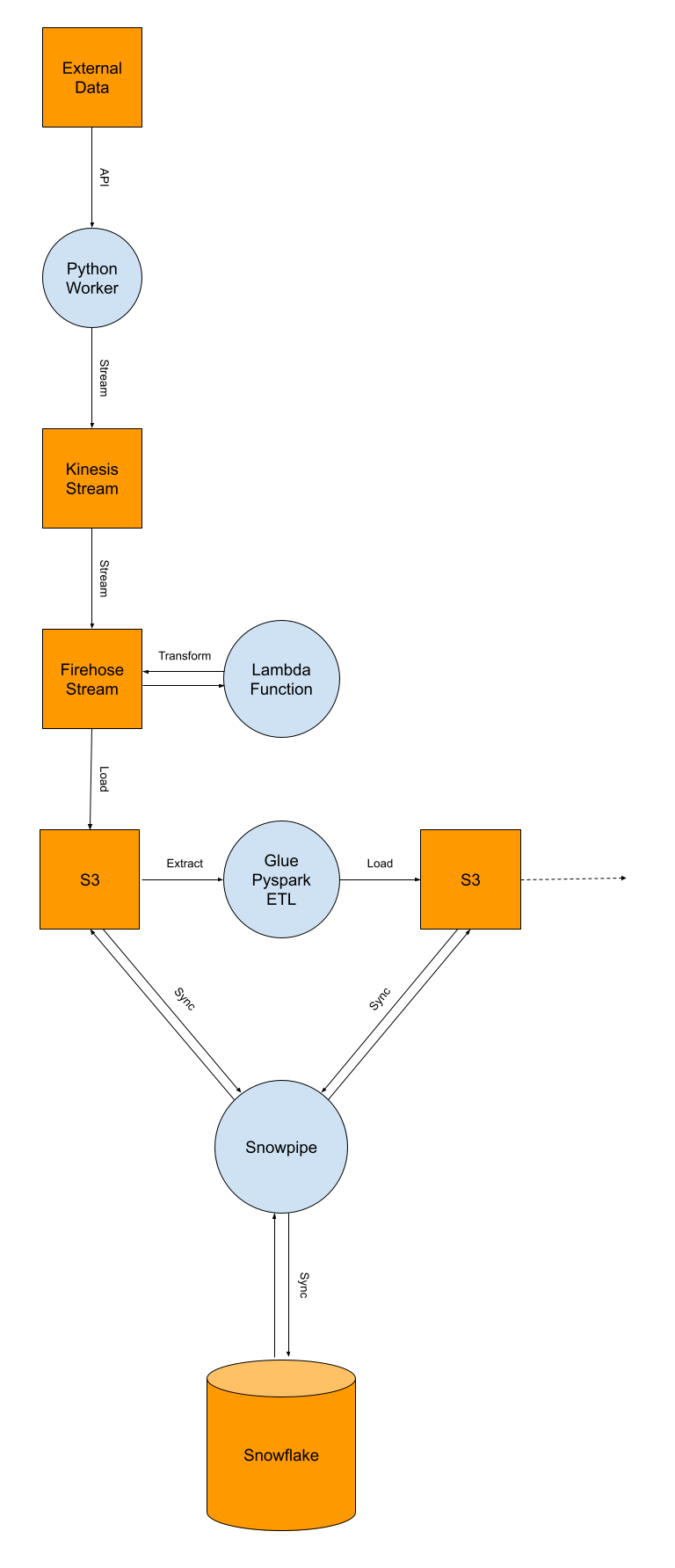
New architecture
To solve the issue of transformations which were incorrect, the raw data needed to be saved. In terms of cost, saving the data raw in S3 was the cheapest, using partitioning schemas that would allow only certain parts of the data to need to be queried. ETL jobs also allowed efficient reprocessing of the data if an issue was discovered in the transformation process.
Snowflake was chosen as the new data as a service solution due to being able to use Snowpipe directly from S3
Explore Others
PhishingLine
PhishingLine
A Linear regression model for detection of phishing pages.
This website
This website
How this website is provisioned and deployed on
AWS
Tactic move to Kubernetes
Tactic move to Kubernetes
A complete shift in orchestration for a
research based startup.